
After having a bit of downtime, CircleCI’s team have been very kind to post a very detailed Post Mortem. I’m a post mortem junkie, so I always appreciate when companies are honest enough to openly discuss what went wrong.
I also greatly enjoy analyzing these things, especially through the complex systems lens. Each one of these posts is an opportunity to learn and to reinforce otherwise abstract concepts.
NOTE: This post is NOT about what the CircleCI team should or shouldn’t have done - hindsight is always 20/20, complex systems are difficult, and hidden interactions actually are hidden. Everyone’s infrastructures are full of traps like the one that ensnared them, and some days, you just land on the wrong square. Basically, that PM made me think of stuff, so here is that stuff. Nothing more.
Database As A Queue
The post mortem states:
Our build queue is not a simple queue, but must take into account customer plans and container allocation in a complex platform. As such, it’s built on top of our main database.
As soon as I read that, I knew exactly what happened. I’d lived this exact problem before, so here’s that story:
At Flickr, we would put everything into MySQL until it didn’t work anymore. This included the Offline Tasks queue (aside: good grief, this post was written in 2008). One day, we had an issue that slowed down the processing of tasks. The queue filled up like it was supposed to, but when we finished fixing the original problem, we noticed that the queue was not draining. In fact, it was still filling up at almost the same rate as during the outage.
When you put tasks into mysql, you have to index them, presumably by some
date field, to be able to fetch the oldest tasks efficiently. If you have
additional ways you want to slice your queues, which both CircleCI and Flickr
did, that index probably contains several columns. Inserting data into RDMS indexes
is relatively expensive, and usually involves at least some locking. Note that
dequeueing jobs also involves an index update, so even marking jobs as in
progress or deleting on completion runs into the same locks. So now you have
contention from a bunch of producers on a single resource, the updates to which
are getting more and more expensive and time consuming. Before long, you’re
spending more time updating the job index than you are actually performing the
jobs. The “queue” essentially fails to perform one of its very basic functions.
Maybe my reading is not quite right on the CircleCI issue, but I’d bet it was something very similar.
In the aftermath of that event at Flickr, we swapped the mysql table out for a bunch of lists in Redis. There were pros and cons involved, of course, and we had to replace the job processing logic completely. Redis came with its own set of challenges (failover and data durability being the big ones), but it was a much better tool for the job. In 2015, Redis almost certainly isn’t the first thing I’d reach for, but options are plentiful for all sorts of usecases.
Coupling at the Load Balancer
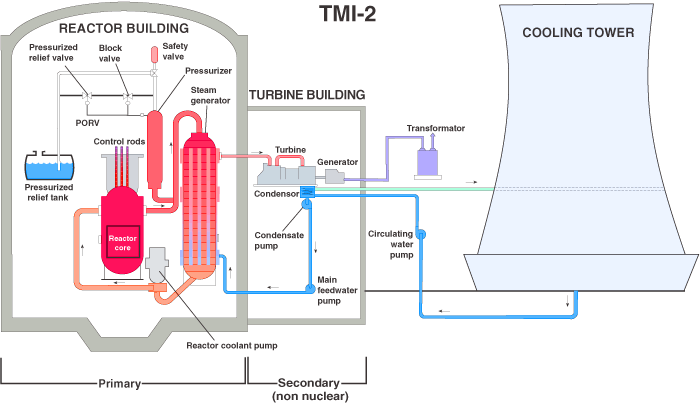
From nrc.gov
First we tried to stop new builds from joining the queue, and we tried it from an unusual place: the load balancer. Theoretically, if the hooks could not reach us, they couldn’t join the queue. A quick attempt at this proved ill-advised: when we reduced capacity to throttle the hooks naturally they significantly outnumbered our customer traffic, making it impossible for our customers to reach us and effectively shutting down our site.
I don’t actually think that’s an “Unusual” place to start at all. If one of the problems is that updates to the queue are becoming too expensive and every additional update is exacerbating the problem, start eliminating updates!
The rest of that paragraph is also not unusual at all. It hints at some details about the CircleCI infrastructure that you would find in an overwhelming majority of infrastructures.
- The public site and the Github hooks endpoint share a loadbalancer
- The processes serving the site and the github hooks run on the same hardware (likely in the same process, as they’re probably just endpoints in the same app)
- There is no way to turn off one without turning off the other
Everyone that knows me knows I LOVE to talk about “unnecessary coupling” in complex systems. This is a really good example.
The two functions have key differences - for one, their audience. Let’s focus on that. The hooks serve an army of robots residing somewhere in Github’s datacenter. The site serves humans. As a general rule, robots can always wait, but making humans on the internet wait for anything is a big no-no. To me, this is a natural place to split things up, all the way through. You can still use the same physical load balancer or ELB instance, but you could make two paths through it - one for the human oriented stuff, another for the robots. Sure, there’ll probably be some coupling farther down the line, like when both processes query the same databases. But at least now the site will only go down if the database is actually inaccessible, not when it has a single contended resource that has nothing to do with serving the site.
A Long Aside: Traffic Segregation At Opsmatic
I do obsess over this stuff, and we’ve already had our fair share of outages with very similar causes. I want to talk a bit about how traffic is currently handled at Opsmatic. This section is full of admissions of having flavors of the same issues as above to further drive the point home that no one’s infrastructure is perfect, certainly not ours. It’s also meant to demonstrate that following some very high level guidelines built on prior learning can go a long way towards improving an infrastructure’s posture in the event of unexpected issues, especially surges.
There are three entry points into Opsmatic:
opsmatic.comis our company’s website and the actual product appapi.opsmatic.comis our REST API, which has historically been used mostly by the app (that’s changing quickly)ingest.opsmatic.comis the API to which our collection agents talk
Here’s an ugly drawing to help you along:
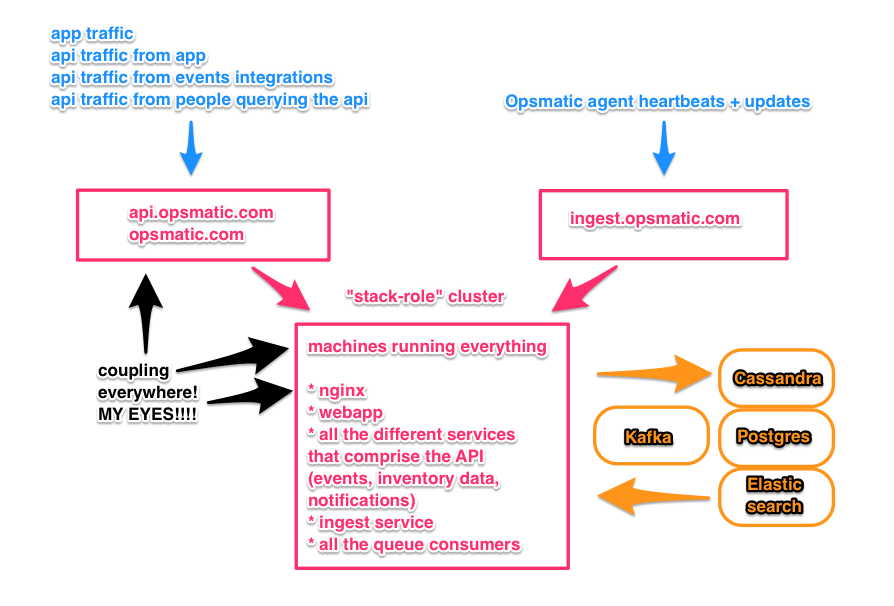
The first two are configured to talk to the same AWS Elastic Loadbalancer (ELB).
The ELB forwards the traffic on ports 80 and 443 to a pool of
instances where nginx is listening. nginx in turn directs the requests.
Traffic to (www.)opsmatic.com goes to one process (a Django app run under
gunicorn), traffic to api.opsmatic.com goes through a completely different
pipeline where it’s teed off to the appropriate backend depending on the URL
pattern. Currently, most of the API traffic is actually coming from humans
using the app. As we flesh out, expand, and document our REST
api, that’s bound to change, at which
point we may put even more buffer between the two traffic streams - separate
nginx processes with appropriate tuning, possibly even separate hardware.
The third ingest.opsmatic.com subdomain is pointed at a completely different
ELB. That’s our equivalent for the Github hooks - the agents are always
running, always sending heartbeats, always sending updates. An unexpected surge
in traffic - for example, an enormous new customer spinning up agents on their
whole fleet of servers all at once without warning us - could certainly
overwhelm the currently provisioned hardware. At the moment, this would take
the app down as well - while the Opsmatic backend is extremely modular, we
currently run all those pieces on the same machines. This limits the operational
overhead at the expense of introducing gratuitously unnecessary coupling.
However, just having the separate ELB gives us recourse in the event of a sudden
surge in robot traffic: we can just blackhole THAT traffic at the ELB and
continue serving site and API read traffic. The robots would be mad, and the
data you were browsing would gradually get more and more stale, but it
beats the big ugly 500 page.
The Opsmatic agent is also built to accumulate data locally if it can’t phone home, so the robots would build up a local version of the change history without losing any data or timestamp accuracy. When we were back up, they’d eventually backfill all that data. This event itself could cause a stampede, but we’ve found it to be a real nice luxury to have.
The modularity combined with reasonably healthy automation allows us to regain our balance quickly. If a certain service is overloading a shared database, we can kill just that service while we work out what’s going on or scrambling to add capacity.
Every Incident Is A Push Towards Self Improvement
The next time this sort of event does happen, we’d likely follow up with a few more steps that have been put off solely due to resource constraints:
- Split up
stack-roleinto smaller pieces, likely along the lines of “human-facing services” and “robot-facing services”. That is, physically separate services that deal with agent traffic from services that deal with human traffic. Possibly we’d go a step further and split up web services from background job processors that pull work from queues. - Split the
opsmatic.comandapi.opsmatic.comload balancers up - A bunch of auxiliary work on various internal tools to better accommodate the fragmentation
The upshot - we currently have a bit of coupling and resource sharing going on for things that really shouldn’t be coupled, but it’s only because we’ve postponed actually splitting everything up in favor of other projects. We are:
- Seconds away from being able to blackhole automation traffic in favor of preserving the app, as well as turning off any background processing that might be causing issues - we can just let that queue grow, turn the service on and off as we try different fixes, etc.
- A few minutes of fast typing away from adding capacity while most of our customers likely don’t even know anything is amiss
- A few more minutes of fast typing from completely decoupling robot traffic from human traffic so that the next surge doesn’t affect the app at all
Hey, that’s pretty good! If we have to fight a fire, at least we can fight it mostly calmly. That, in and of itself, is huge. Being able to isolate the problem and say “OK, this is the problem, it is not the whole infrastructure, it is contained to a particular set of actions and now we’re going to work on it” is huge for morale during an outage. I do not envy the feeling the CircleCI team must have felt when attempts to bring back the queue took down the main site.
I used the word “posture” earlier - I have in mind a very specific property when I use that word. It’s not so much about “how resilient to failures is our infrastructure?” but rather “how operator-friendly is our infrastructure during an incident?” Things like well-labeled kill swtiches, well segmented traffic, well behaved background and batch processing systems that operate indepenently from the transactional part of the app go a long way towards decreasing stress levels during incidents.
Conclusion?.. What is this post, even..
This turned into a bit of a rambling piece. Hope you found it interesting. Here’s my key takeaways:
- You can use a database as a queue, but you should keep a close eye on the timing data for the “work about work” your database is doing just to get jobs in and out. One day, you’re going to have a bad time. That is ok. It’ll make you stronger.
- It pays to think about the sources of traffic to your infrastructure and how they interact with each other. Over time, it pays even more to have parallel, as-decoupled-as-time-allows paths through your system, any of which can be shut off in isolation.
- Every infrastructure is a work in progress; computers are hard, and distributed systems are even harder



 This
This 




 While discussing what to do for a Free Friday project,
While discussing what to do for a Free Friday project, 

{kind=link}
{kind=link}